Artificial Intelligence (AI) and machine learning (ML) are making inroads into virtually every field of human endeavor, including the world of video content generation, distribution and display. Recently SMPTE hosted a webinar titled “Beyond the Skynet Myth: Discovering the Reality of How AI is Used Today in Content Creation & Distribution, and the Possibilities for Tomorrow.”
![]()
The webinar was presented by Jason Brahms of Video Gorillas and Lydia Gregory from Feedforward AI. I’m not an AI expert and wound up watching the recorded webinar a second time on the SMPTE website to make sure I understood what the speakers were saying.
Video Gorillas is headquartered in Los Angeles with engineering based in Kiev. One of it’s main AI products is called “Gorilla Brain.” Gorilla Brain is a proprietary triple neural network-based system that maps highly abstract visual features from media, obtained through supervised and unsupervised learning, into a language model.
Its self-learning framework enables development of content-aware media indexing and search systems for both user-generated and professional content. Gorilla Brain is able to detect thousands of different objects, shapes, colors, actions, and sentiment in images and video.
Video Gorillas’ customers use Gorilla Brain in a wide variety of ways, including:
- Contextual targeting (of both video content and advertisements)
- Smart content censorship for movies and images
- Trademark and brand detection
- Real-time content detection
- Object detection or replacement
FeedForward AI is a London-based machine learning and deep consultancy that aims to bridge the gap between businesses and cutting-edge research. After watching the webinar twice, I can appreciate how a non-AI expert (i.e. virtually everyone in the SID and SMPTE communities) would need help to apply AI or ML to either research or business needs.
Skynet is the villainous computer system in the Terminator series of movies that sees human beings as an unnecessary intrusion into its mission of protecting the world from threats. Another notorious AI computer was HAL 9000 of the movie 2001: A Space Odyssey who attempts to kill the astronauts that try to shut him down when he malfunctions. Neither of these computers have any relationship with the use of AI in video production today. All the AI discussed in this webinar was directed by a person and not self-directed by the AI computer system. I do wish, however, that Jason had used the word “Scary” a little less often in his talk.
 Content Creation Chain for Video and Cinema
Content Creation Chain for Video and Cinema
According to the presenters, AI is already being integrated into products to make the creative process more intuitive, speed up its less creative elements and accelerate the process from idea to release. AI and ML are already used in several of the links in the content creation chain and, in the future, will be used in virtually every link.
One of the non-creative processes that is currently being speeded up is searching an image or video database for content to use. For example, Lobster Media claims to have 37 Billion user-generated photos and videos from more than nine social networks. If you need, for example, a photo or video of a left-handed gorilla, there may well be one among these 37 billion images or videos but how do you find it? AI can speed up the search process. Eventually, it may be possible for AI to take over the entire process, making it unnecessary for anyone to ever see any of those 37 billion images unless it is exactly the image they want. Since, according to Lydia, about 600 hours of content is uploaded to social media networks every minute, it would take about 36,000 people to watch just the new content in real time – impossible.
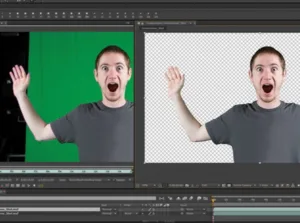
Rotoscoping an image (Credit: Russ Fairley at Videomaker.com)
Rotoscoping is another tedious process that AI can help. Rotoscoping is the process of separating a desired part of the image from the background. In the image, the desired image is the person with his arm raised and the green screen and black area are the undesired background. Automatic rotoscoping with a green screen is pretty good but not always perfect. For example, wrinkles in the green screen can sometimes cause problems, as can areas outside the green screen such as the hand in the example image. In content not shot with a green screen, rotoscoping to remove the background is a very tedious process. Without AI, it must be done for every frame of the content. For a 10 second cinema clip, that would mean it would need to be done on 240 frames. Very tedious, time consuming and expensive.
According to Jason, another step in the chain where AI is currently used a little but will be used more in the future is in the CF (content finishing) step. Currently it is mostly used in the compliance step (e.g. compliance with SMPTE standards or the requirements of a distributor such as HBO) and auto adaption so the content can be shown with different aspect ratios, frame rates and bit rates. Future uses in the CF step are in translation (with increased accuracy of the translation using the context of audio and picture analysis); object recognition; and sentiment analysis (using facial recognition to determine emotional content). These techniques can be used in preparing versions for foreign consumption. For example, in strict Muslim societies, violence is tolerated in video and cinema content but sexually suggestive action is strictly forbidden.
 Demo of dataset generator tool for training object detection and semantic segmentation algorithms.
Demo of dataset generator tool for training object detection and semantic segmentation algorithms.
There were a number of other future applications for AI in all phases of content creation and distribution discussed in the 90 minute webinar, including both the video and audio content. Perhaps the most interesting was the automatic generation of high resolution images from verbal descriptions.
The first step in this generation is extracting the general features from real images. This involves training the machine learning software to identify different objects. This training involves the ML software looking at thousands or, better yet, hundreds of thousands of images. Objects in the image are then assigned a labels and can be color coded in the segmented image. For example, in the above image, “desk chair,” “lounge chair,” “sofa,” “coffee table,” “florescent light,” “wall,” “ceiling,” “tile floor,” “rug,” “column,” “door,” “window,” etc. are all given labels and shown in different colors. Since there are millions of different objects in the world, millions of different labels need to be assigned and trained for.
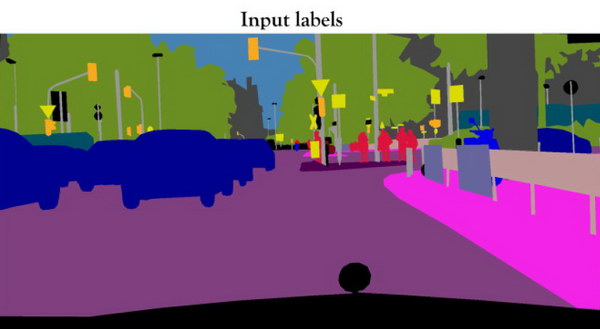 Input labels used to synthesize a high resolution image
Input labels used to synthesize a high resolution image
The next step is to generate a cartoon-like image that shows the AI image generation software what objects you want placed where, like the image shown above. This cartoon image can come from a computer graphics simulation but the one used as an example came from a real image that was broken down into its various components.
 Synthesized image from the input labels.
Synthesized image from the input labels.
The final step is for the AI software to insert realistic objects to match the input labels in the cartoon image. This synthesized image need not look like the original used to generate the cartoon and, in fact, many different images can come from the same cartoon and label set. This example image the webinar authors took from a paper by Ting-Chun Wang et. al. at Nvidia and the University of California at Berkeley.
 This GIF shows four different images generated by the AI software from the same labels and some human intervention. A second GIF on the project website shows five additional images.
This GIF shows four different images generated by the AI software from the same labels and some human intervention. A second GIF on the project website shows five additional images.
In the on-line version of this paper, the authors showed nine alternative versions of this image that can be generated from the same cartoon and input labels through interactive editing. The image above shows four of these versions. Variations between images include a cobblestone street and other pavement types, different pavement markings, different car colors, trees with no leaves on them, sunshine coming from different angles, etc.
 Images generated from the same labels and cartoon by three different algorithms.
Images generated from the same labels and cartoon by three different algorithms.
The authors of this paper at Nvidia and UC Berkeley are not the only group working on this synthetic image technology They also gave an example of how different algorithms can give different images of different qualities. The “ours” in this image refers to the Nvidia algorithm and their version of the synthesized images are clearly the best, even if it isn’t yet of cinema quality.
 Person-to-person video translation. The Puppet Master is on the left and the artificial image that follows the Puppet Master is on the right.
Person-to-person video translation. The Puppet Master is on the left and the artificial image that follows the Puppet Master is on the right.
Perhaps the creepiest application of AI, machine learning and automatic video image generation discussed in the webinar was the person-to-person video translation example, also known as the Puppet Master. Here, one person, called the puppet master, was captured on video, complete with voice, gestures, head and body motion, etc.
The AI software turned this into a video image of a different person giving the same speech with the same gestures. (The full video is shown on the recorded webinar, which is free for SMPTE members.) Clearly this current demo wouldn’t fool anyone. But since it is certain that further research will a) improve the video quality; b) improve the speed so it is done in real time; and c) substitute the targeted person’s voice for the puppet master’s voice; this will have serious implications for the future.
The webinar also discussed a simpler but related system. In this, they used a speech by Barack Obama as the source; did speech-to-text conversion of his talk; automatically translated the text into Japanese; used text-to-speech conversion to generate the Japanese language audio; and then added the Japanese audio to the video. As an extra, they did a computer image manipulation lip-sync on Obama’s face so it looked like he was speaking Japanese, even to a Japanese lip reader.
All of the discussion in the webinar was of people directing AI and ML-based software systems to do things and there was no real prospect of self-directed AI systems like Skynet or HAL 9000 with these AI-based video editing technologies. At the end of the webinar, Lydia’s comment was “Wow, yeah, cool!” I certainly agree with her. But I still wish Jason hadn’t had to use “Scary!” so many times during his portion of the talk. –Matthew Brennesholtz